Enabling robots to execute novel manipulation tasks zero-shot is a central goal in robotics. Most existing methods assume in-distribution tasks or rely on fine-tuning with embodiment-matched data, limiting transfer across platforms. We present NovaFlow, an autonomous manipulation framework that converts a task description into an actionable plan for a target robot without any demonstrations. Given a task description, NovaFlow synthesizes a video using a video generation model and distills it into 3D actionable object flow using off-the-shelf perception modules. From the object flow, it computes relative poses for rigid objects and realizes them as robot actions via grasp proposals and trajectory optimization. For deformable objects, this flow serves as a tracking objective for model-based planning with a particle-based dynamics model. By decoupling task understanding from low-level control, NovaFlow naturally transfers across embodiments. We validate on rigid, articulated, and deformable object manipulation tasks using a table-top Franka arm and a Spot quadrupedal mobile robot, and achieve effective zero-shot execution without demonstrations or embodiment-specific training.
3D Point Cloud & Actionable Flow from Generated Video
Note: The visualized end-effector is offset from the physical one due to longer gripper fingers used in real-world experiments.
Initial Observation
Generated Video
Execution Video (1x speed)
Flow generator pipeline: Given an initial image and a task prompt, a video model is used to generate a video of the plausible object motion. This video is then processed by pretrained perception modules to distill an actionable 3D object flow. This involves (1) lifting the 2D video to 3D using monocular depth estimation,
(2) calibrating the estimated depth against the initial depth,
(3) tracking the dense per-point motion using 3D point tracking,
and (4) extracting the object-centric 3D flow via object grounding.
Flow executor pipeline. The initial end-effector pose is determined from grasp proposal candidates. Robot trajectories are then planned based on the actionable flow considering costs and constraints, and subsequently tracked by the robots.


Cup on Saucer: A human hand picked up the small blue cup, raised it, and gently placed it on the red saucer.


Open Drawer: A human hand grasps a black drawer handle and smoothly pulls it out of the drawer. The drawer should open in a straight line without moving forward or backward. The human hand should not visually obscure the drawer handle.


Hang Mug: A human hand picks up the mug and hangs it on the wooden stand on the right. The human hand should not visually obscure the mug.


Block Insertion: A human hand picks up the yellow block and inserts it precisely into the center of the plate with the blue block to the right. The human hand should not visually obscure the yellow block.


Water Plant: A human hand grasps the green water cup, lifts it, and then moves smoothly to water the plant. The camera remains stationary throughout. The hand does not visually obscure the drawer handle.


Open Lid: A human hand grasps the transparent lid of a pot and lifts it straight up. The camera remains stationary. The hand does not visually obscure the drawer handle.


Straighten Rope: A human hand straightens the rope. The human hand should not visually obscure the rope.
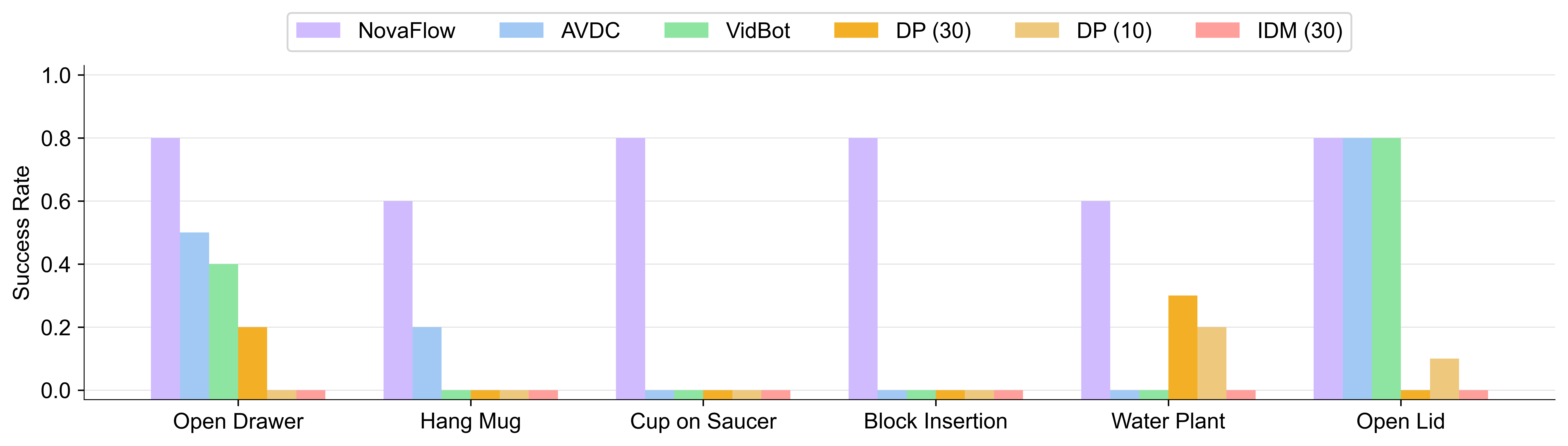
Experiment Results:
NovaFlow consistently achieves the highest success rate across all real-world manipulation tasks.
It outperforms other demonstration-free methods like AVDC and VidBot. Notably, NovaFlow also surpasses data-dependent methods, including Diffusion Policy (trained with 10 and 30 demonstrations) and an Inverse Dynamics Model, in every task evaluated.

Failure Mode: We identify four primary failure modes: video failures from implausible generated content, tracking failures from inaccurate 3D point tracking (e.g., due to occlusion), grasp failures from incorrect object interaction, and execution failures from trajectory errors like collisions. Most failures occur in the last mile --grasping and execution-- highlighting that physical interaction is the main bottleneck, similar to a sim-to-real gap. Future work could address this with closed-loop feedback for dynamic replanning.